Inputdaten
Die Eingabedaten der Scatterplotanalyse bestehen aus einer X- und einer Y-Koordinate, von denen die Beziehung zueinander untersucht werden soll.
Dafür können Stell- sowie Ergebnisgrößen verwendet werden. Als weiterer Eingabewert wird eine Klasse benötigt. Dabei kann es sich um eine kategorische Größe handeln oder die Clusterzuordnung des Clustering.
In Abbildung 1 ist das Eingabefeld beispielhaft dargestellt.
Abbildung 1 - Beispieleingabe Scatterplotanalyse
Interpretationsbeispiel
Die Scatterplotanalyse kann genutzt werden, um schnell einen Eindruck über Einflüsse von Stellgrößen im Kontext von Clusterzuordnungen oder anderen Kategorischen Einflussfaktoren auf verschiedene KIPs (z. B. Szenarien) zu bekommen.
In dem folgenden Beispiel wird der Einfluss des Produktionsvolumens gefiltert nach der Clusterzuordnung auf die Stillstandzeit der Produktion dargestellt.
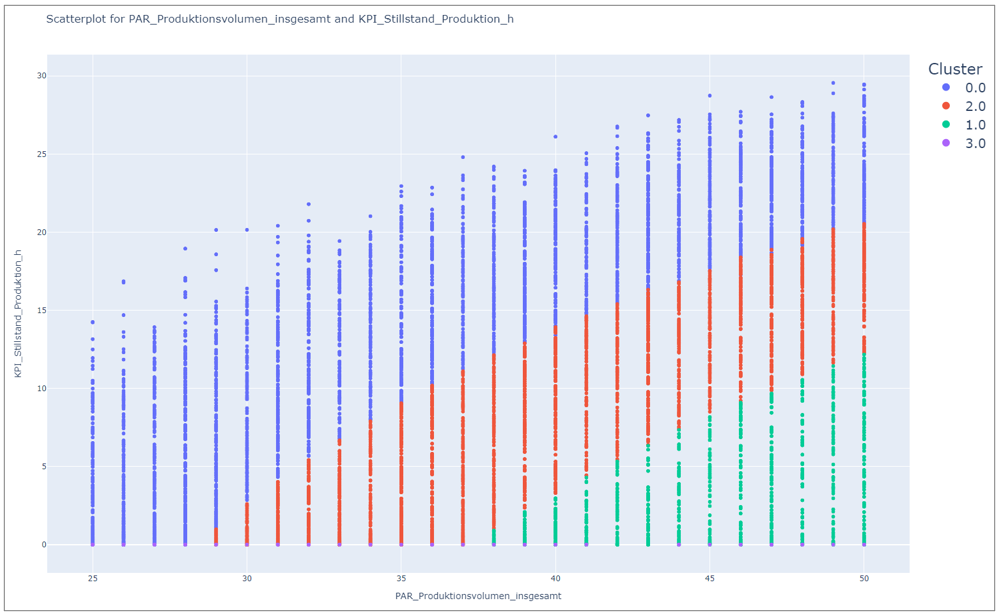
Abbildung 2 - Scatterplotanalyse
Durch die Abbildung 2 wird deutlich, dass Cluster 0 in dem gebannten Bezug die schlechteste Performanz hat und Cluster 1 und 3 die beste, da trotz hohem Produktionsvolumen eine niedrige Stillstandzeit erreicht wird.
Jedoch fällt auf, dass Cluster 3 vermutlich nur eine kleine Anzahl an Experimente zugeordnet werden, da nur einige wenige Punkte, dessen Stillstandzeit 0 ist, am unteren Rand erkennbar sind.
Der schräge Verlauf der Trennlinien lässt auf einen mehrdimensionalen Zusammenhang schließen –mindestens ein anderer Faktor besitzt auch noch Einfluss auf die Clusterzuordnung.
Es sollten in dem Kontext folglich weitere Analysen mittels mehrdimensionaler Verfahren durchgeführt werden. Z. B. Radar-, Parallelplots oder Klassifikationsbäume.
© SimPlan AG - AG Hanau HRB 6845 - info@simplan.de - www.simplan.de