Inputdaten
Bei der Regressionsanalyse werden drei Eingabegrößen benötigt. Zum einen ein Ergebnisparameter, der auf der X-Achse abgebildet wird. Zum anderen eine Faktorgröße, welcher auf der Y-Achse dargestellt wird.
Das Verhalten dieser beiden Eingaben wird über eine Filterfaktorgröße gefiltert (Abbildung 3). Bei der Filterfaktorgröße kann es sich auch um die Clusterzuordnung aus dem Clustering handeln.
In Abbildung 1 ist das Eingabefeld beispielhaft dargestellt.
Abbildung 1 - Beispieleingabe der Regressionsanalyse
Parametrisierung
Die Parametrisierung bei der Regressionsanalyse kommt nur zum Einsatz, wenn es sich um eine kontinuierliche Filtergröße handelt bzw. die einzelnen Ausprägungen der Filtergröße mehr als 10 sind.
Kontinuierliche Filtergrößen sind zum Beispiel Prozentangaben, Zeiten oder sehr fein aufgelöste Stellgrößen.
In diesem Fall wird der Parameter Kontinuierliche-Filtergröße auf „True“ gesetzt und mit dem Parameter Filter-Intervalle wird die Anzahl der verwendenden Filterintervalle festgelegt.
Die Anzahl der festgelegten Filter sollte nicht mehr als 10 betragen. In Abbildung 2 sind die verfügbaren Parameter beispielhaft dargestellt.

Abbildung 2 - Parametrisierung der Regressionsanalyse
Interpretationsbeispiel
Mit der Regressionsanalyse können lineare Zusammenhänge (rote Linie) in großen Datenmengen erkannt und über Koeffizienten (rote Formel in der oberen rechten Ecke) quantifiziert werden.
In Abbildung 3 ist eine Regressionsanalyse für die Beziehung zwischen den Parametern „Anteil_Modell_A_an_der_gesamten_Produktion“ und „Stillstand_Produktion_h“ gefiltert nach den berechneten Clustern dargestellt.
Über die Formel an der entsprechenden Grafik lassen sich auch Prognosen treffen. Werden die Gesamtdaten betrachtet, kann ein leichter linearer Zusammenhang erkannt werden.
Hier führt eine Erhöhung das prozentualen Anteils A an der gesamten Produktion um 1% zu einer prognostizierten Erhöhung der Stillstandzeit um 20 Minuten (0.33*1 = 0.33 [Stunden] = 20 [Minuten]).
In den nach den Clustern gefilterten Ansichten wird auch deutlich, dass Cluster 1 deutlich stabilere Experimente umfasst und auch eine maximale Stillstandstandzeit von 12 Minuten besitzt.
Hier führt eine Erhöhung des Anteils A um 1% nur zu einer prognostizierten höheren Stillstandzeit von 6 Minuten (Cluster 0: ca. 20 Minuten, Cluster 2: ca. 10 Minuten).
Dadurch wird auch deutlich, dass die Experimente des Clusters 1 in Bezug auf die Stillstandzeit und den Anteil von Modell A die beste Performanz liefern.
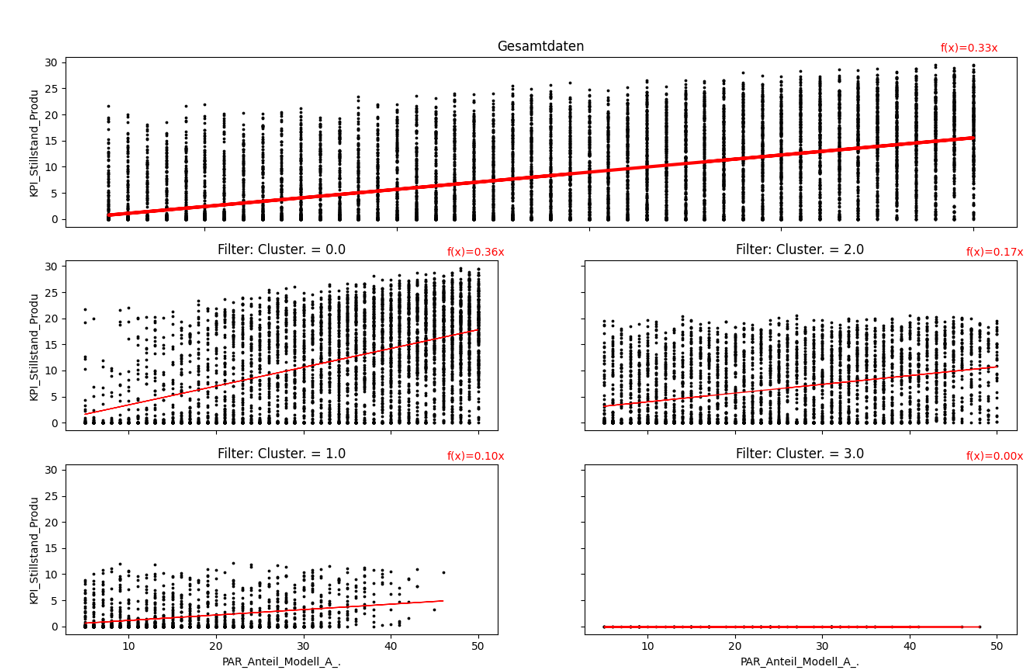
Abbildung 3 - Regressionsanalyse
© SimPlan AG - AG Hanau HRB 6845 - info@simplan.de - www.simplan.de