Inputdaten
Bei der Data-Mining-Methode des Klassifikationsbaums teilen sich die Eingabedaten in zwei Gruppen auf. Als erstes die Cluster-ID, welche die Clusterzuordnung des Clustering ist.
Weitere Eingaben werden hier nicht benötigt. Die zweite Kategorie sind die Faktorgrößen, welche zur Erklärung der Clusterzuordnung verwendet werden sollen. In Abbildung 1 ist das Eingabefeld beispielhaft dargestellt.
Abbildung 1 - Beispieleingabe Klassifikationsbaum
Parametrisierung
Als Parameter stehen dem Klassifikationsbaum die Maximale-Tiefe und die Minimale-Blatt-Größe zur Verfügung.
Bei der Maximalen-Tiefe handelt es sich um den Parameter, der angibt wie viele Ebenen der Klassifikationsbaum hat bzw. welche Tiefe.
Die Minimale-Blatt-Größe gibt an wie viele Experimente einer Entscheidungsregel minimal zugeordnet werden müssten, damit die Einteilung vorgenommen wird.
In Abbildung 2 ist eine beispielhafte Parametrisierung für einen Klassifikationsbaum mit einer maximalen Tiefe von 5 und einer minimalen Blattgröße von 50 abgebildet.
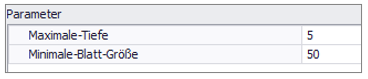
Abbildung 2 - Parametrisierung Klassifikationsbaum
Interpretationsbeispiel
Der Klassifikationsbaum ist ein Verfahren zur Regelextraktion für Realszenarien.
Durch ihn können nach der Identifikation des Clusters mit der gewünschten Performanz Regeln identifiziert werden, welche in dem Realweltszenario zu diesem Ergebnis führen.
Oder im Falle eines schlechten Clusters, welche Parametereinstellungen in dem System vermieden werden sollten.
In dem Beispiel in Abbildung 3 (Ausschnitt des Klassifikationsbaums) gehen wir davon aus, dass Cluster 1 durch vorherige Analysen als sehr gut in Bezug auf die Performanz eingestuft wurde.
Durch den Klassifikationsbaum ist es möglich Regeln abzuleiten, welche in dem Realszenario zu dieser Performanz führen. Dafür wird das „Blatt“ gesucht, welches einen Großteil der Experimente des Clusters 1 enthält.
Von diesem Blatt aus kann die Regel nun abgeleitet werden, indem wir dem roten Pfad bis zu dem letzten Blatt folgen.
Daraus ergeben sich folgende Einstellungen für das Szenario, wenn die Performanz des Cluster 1 erreicht werden soll:
Parameter |
Wert |
Anteil_Modell_B_an_gesamter_Produktion |
<29.5% |
Produktionsvolumen_insgesamt |
>37.5 Einheiten pro Stunde |
Anteil_Modell_A_an_gesamter_Produktion |
<28.5% |
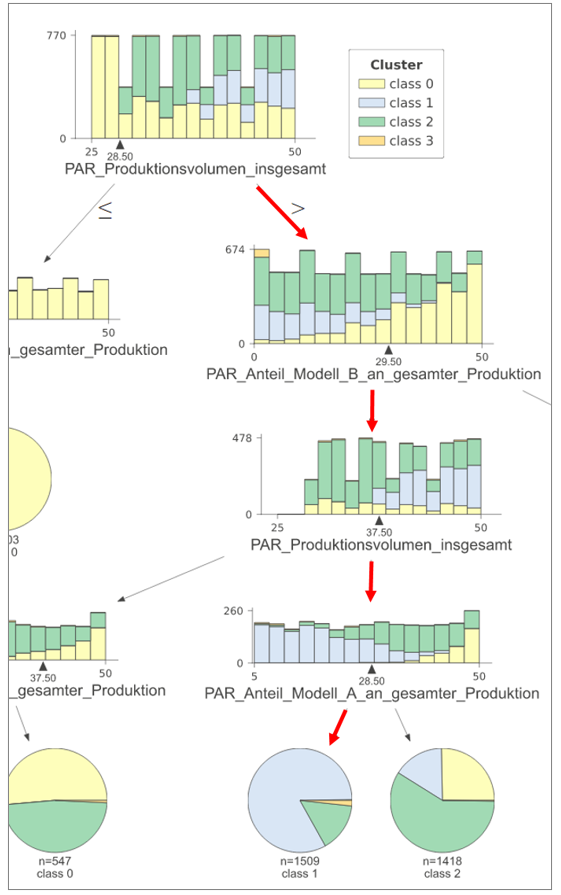
Abbildung 3 - Klassifikationsbaum
Abbildung 4 stellt einen kompletten Klassifikationsbaum mit der Tiefe von 5 dar. Dadurch wird deutlich, welche Größe die Klassifikationsbäume annehmen können.
Aber auch die Möglichkeiten verschiedene Regeln für unterschiedliche Szenarien abzuleiten sind dadurch vielfältig.
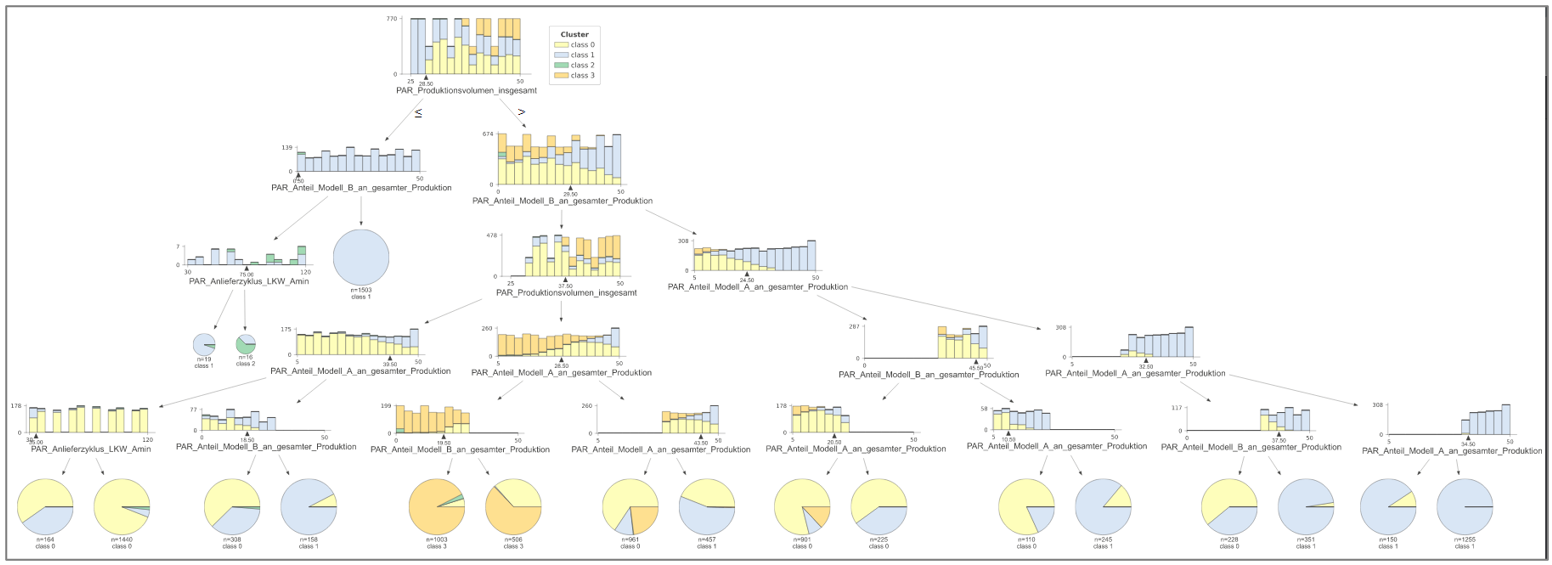
Abbildung 4 - Kompletter Klassifikationsbaum
© SimPlan AG - AG Hanau HRB 6845 - info@simplan.de - www.simplan.de