Inputdaten
Als Eingabe des Clustering werden die Clustering-Zielgrößen und Daten verwendet. Die Clustering-Zielgrößen sind die Ergebnisgrößen, welche als relevant und interessant eingestuft wurden.
Auf Basis dieser Ergebnisgrößen teilt der Algorithmus die Daten in die entsprechenden Cluster ein. Die Daten sind alle weiteren Größen der Simulationsstudie.
In Abbildung 1 ist das Eingabefeld beispielhaft dargestellt.

Abbildung 1 - Beispieleingabe des Clustering
Parametrisierung
Als Parameter stehen im Clustering zum einen die Clusteranzahl und das Clustering-Verfahren zur Verfügung. Die Clusteranzahl gibt an in wie viele „Gruppen“ die Daten eingeteilt werden.
In der Abbildung 3 zum Beispiel wurden die Daten in 4 Cluster eingeteilt. Die Auswahl der Anzahl an Cluster erfolgt über den Silhouettenkoeffizienten.
Die gängige Methode besteht darin die Clusteranzahl auszuwählen, welche den durchschnittlich höchsten Silhouettenkoeffizienten (rot-gestrichelte Linie) und eine möglichst gleichmäßige Verteilung
der Silhouettenkoeffizienten über die Cluster erreicht. Der zweite Parameter gibt das mathematische Verfahren an, welches der Einteilung in die Cluster zugrunde gelegt wird.
Zur Auswahl stehen K-Means und Gaussian-Mixture-Modelle (GMM), welche unterschiedliche Distanzen zur Berechnung der Clusterzugehörigkeit benutzen.
In den meisten Fällen ist die Performanz des GMM-Algorithmus besser und daher sollte dieser bevorzugt verwendet werden. In Abbildung 2 ist eine Beispielparametrisierung für 5 Cluster mit GMM dargestellt.
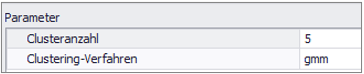
Abbildung 2 - Parametrisierung Clustering
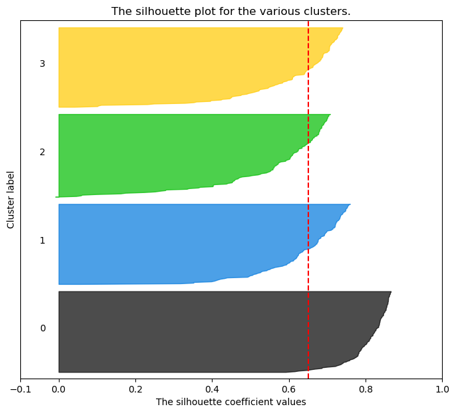
Abbildung 3 - Visualisierung des Silhouettenkoeffizienten
© SimPlan AG - AG Hanau HRB 6845 - info@simplan.de - www.simplan.de