Input data
The clustering target variables and data are used as input of the clustering. The clustering target variables are the result variables that have been classified as relevant and interesting.
Based on these result variables, the algorithm divides the data into the appropriate clusters. The data are all other variables in the simulation study.
Figure 1 shows an example of the input field.
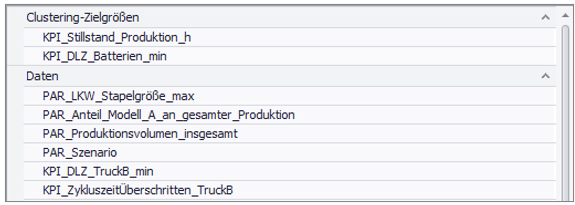
Figure 1 - Example input of the clustering
Parametrization
The parameters available in the clustering are on the one hand the cluster number and the clustering method. The number of clusters indicates how many "groups" the data are divided into.
In Figure 3, for example, the data was divided into 4 clusters. The selection of the number of clusters is done by the silhouette coefficient.
The common method is to select the number of clusters that achieves the highest average silhouette coefficient (red dashed line) and the most even distribution of silhouette coefficients across the clusters.
The second parameter specifies the mathematical method on which the classification into clusters is based.
Choices include K-Means and Gaussian mixture models (GMM), which use different distances to calculate cluster membership.
In most cases, the performance of the GMM algorithm is better and therefore it should be preferred. Figure 2 shows an example parametrization for 5 clusters using GMM.
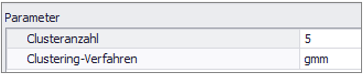
Figure 2 - Parametrization Clustering
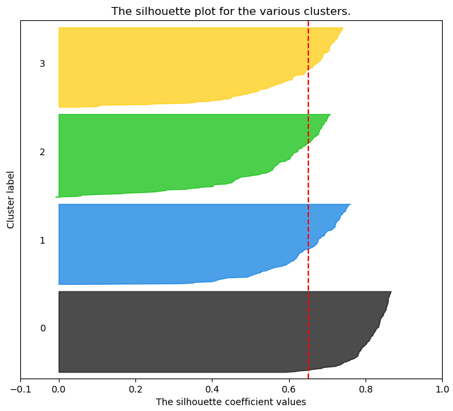
Figure 3 - Visualization of the silhouette coefficient
© SimPlan AG - Hanau District Court, Commercial Register (Part B) 6845 - info@simplan.de - www.simplan.de/en